

In case you missed our last post, we released a platform of open drug data pipelines called SageRx on GitHub. It’s open source, but I know from experience that I star a bunch of repos that seem interesting at the time and never go back to look at how they work. This post attempts to summarize the tools we chose to use to create SageRx and explain how it all comes together.
Fair warning: this article is somewhat technical, so if you aren’t really interested in knowing how software works “under the hood”, you might want to skip this one. Or don’t! You might learn something and get hooked on software development!

Overall architecture
Docker is used to containerize the tools below. Spinning up SageRx is as simple as a few initial setup steps and then a couple of docker-compose up statements.
See detailed installation instructions in the GitHub repo here: https://github.com/coderxio/sagerx
Flow of data
1. Airflow
⬇️
2. PostgreSQL / pgAdmin
⬇️
3. dbt
This simplistic diagram is not entirely correct because dbt also updates PostgreSQL with tables created from the transformations… but hopefully you get the general idea.
I will try to explain some highlights specific to SageRx from each of these steps in the sections that follow.
1. Airflow
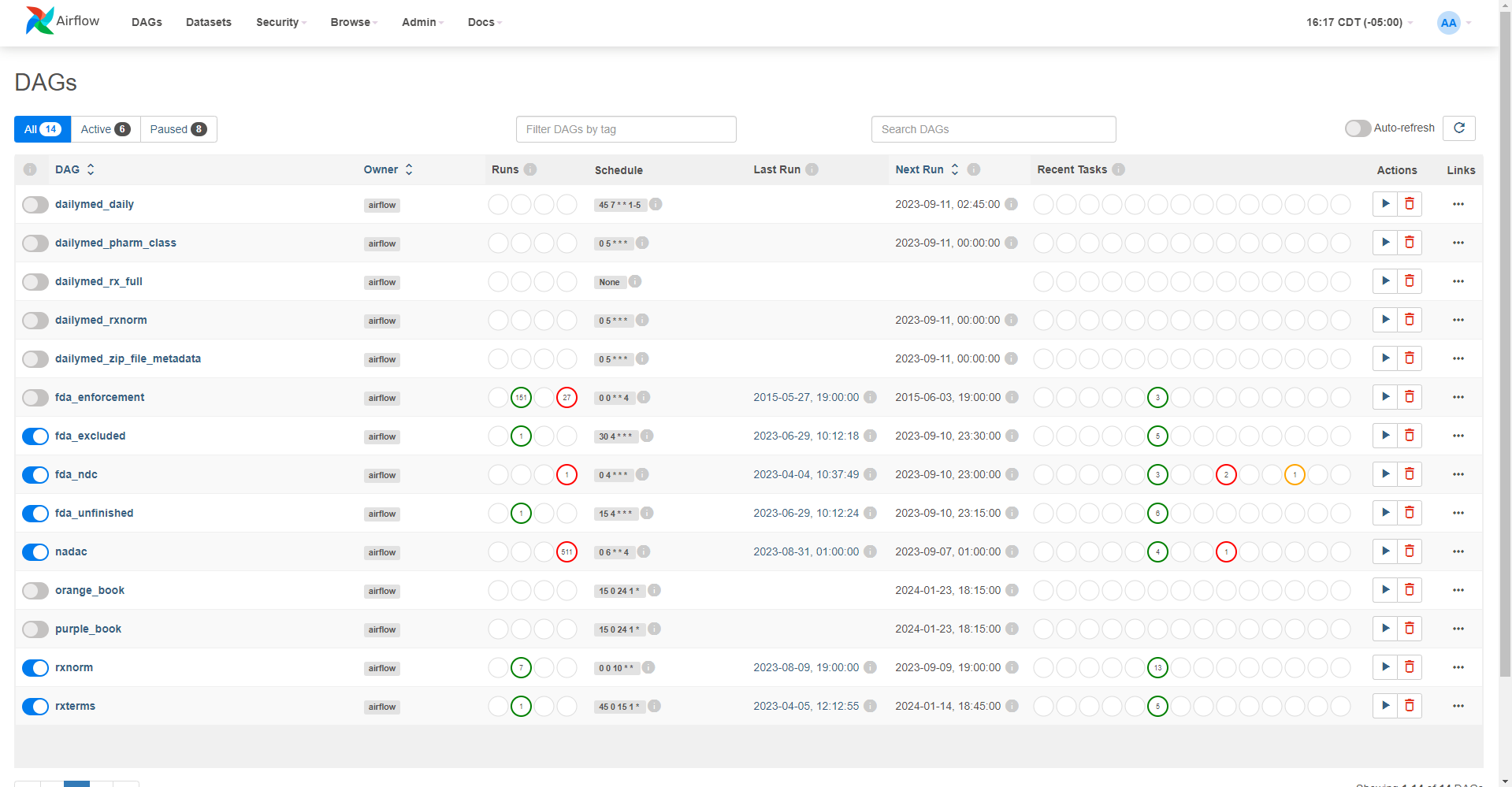
Airflow is the data pipeline tool we chose for this project because it is open source, supported by Apache, and seems to be widely used by a variety of industries. All of the business logic relating to where the raw open drug data lives (NLM / CMS / FDA / etc), what format it is stored in, how often it is updated, how to unpack and manipulate it, etc is stored within Airflow “DAGs” (directed acyclic graphs) - which are basically just Python scripts.
Airflow is used for the Extraction and Loading (EL) of the overall Extract-Load-Transform (ELT) data engineering process.
Timing of data source updates
The update timing of data sources is maintained here. Some data sources are updated weekly, others monthly, others yearly, etc. With the flip of a switch, you can automate recurring updates of any data source.
Authentication
Select data sources (RxNorm) require a free license key even though the parts of the data used from the source are open. Airflow handles the authentication steps required for these scenarios.
Changing file names
Some raw data file names change with every release - possibly including a date at the very least. Some files aren't regularly updated on the same day of the month and require an initial API call to determine the most recent file before downloading.
Back-loading of data
Some data sources have data going back several years. In situations where loading all of this data is beneficial (NADAC, for instance), Airflow can automate the backfill process of historic data.
Unzipping of files
Some data sources use zipped files one or more layers deep. Airflow, combined with custom functions, handles unzipping these files and only loading the necessary ones into the database.
Loading into the database
SageRx utilizes the Postgres COPY function to load data directly from a file into a database. We think this is the most efficient way to load data into a database. This can handle the vast majority of file types (CSV, TSV, RRF, etc).
In scenarios where the COPY function can't handle a file type (Excel files, for instance), we use Python / pandas to transform the data into a format that can be loaded into the database.
2. PostgreSQL / pgAdmin
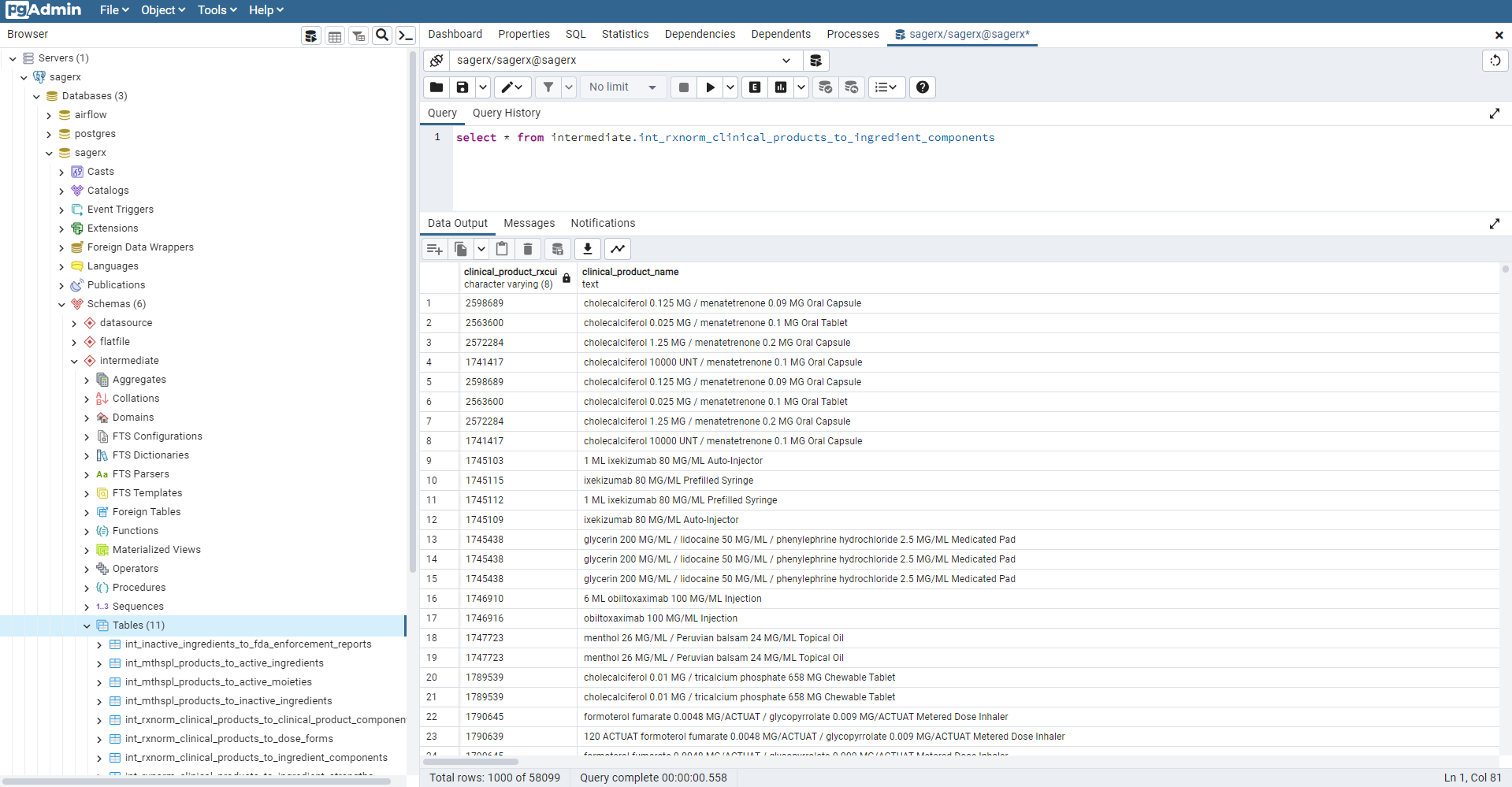
Currently, all data ends up in a PostgreSQL database. We chose PostgreSQL because it is open source, supported by a large community, and has excellent documentation.
We suspect that there will be a need for connectors to other types of databases (cloud, data lake, etc), but initially we wanted to keep it simple.
Schemas
The three main schemas in the PostgreSQL database are:
datasourcestagingintermediate
All of the raw data from Airflow ends up in the datasource schema in as close to its raw format as possible. There may be slight differences solely due to column type, but the intent is to leave it in raw format.
From there, it is transformed by dbt (as described in step 3 below) and the resulting data ends up in the staging and intermediate schemas. More information about this in the dbt section below.
Eventually, we may have some data mart data in the mart schema and possibly a separate flatfile schema for data meant to be loaded into flat files for easy download.
Custom functions
NDC formatter
Due to the need for common transformations like taking a hyphenated NDC and converting it to NDC11 format, we created custom Postgres functions to handle this.
We made this decision prior to implementing dbt, so a future optimization may be converting these functions from Postgres to dbt. However, they come in handy when writing queries directly in pgAdmin.
select ndc_to_11('1234-5678-90')
/* returns 01234567890 */Connecting to the database
Using pgAdmin
It is not necessary to use pgAdmin to connect to the database, but it makes it easy to run some quick queries and has (in our opinion) a great user interface.
By default pgAdmin is hosted on port 8002.
Connecting directly
Since we use Postgres as the database, connecting to a hosted version of SageRx is just like connecting to any other Postgres database.
By default, the connection information is configured as listed below.
server: <<server_address>>:5432
username: sagerx
password: sagerx
3. dbt
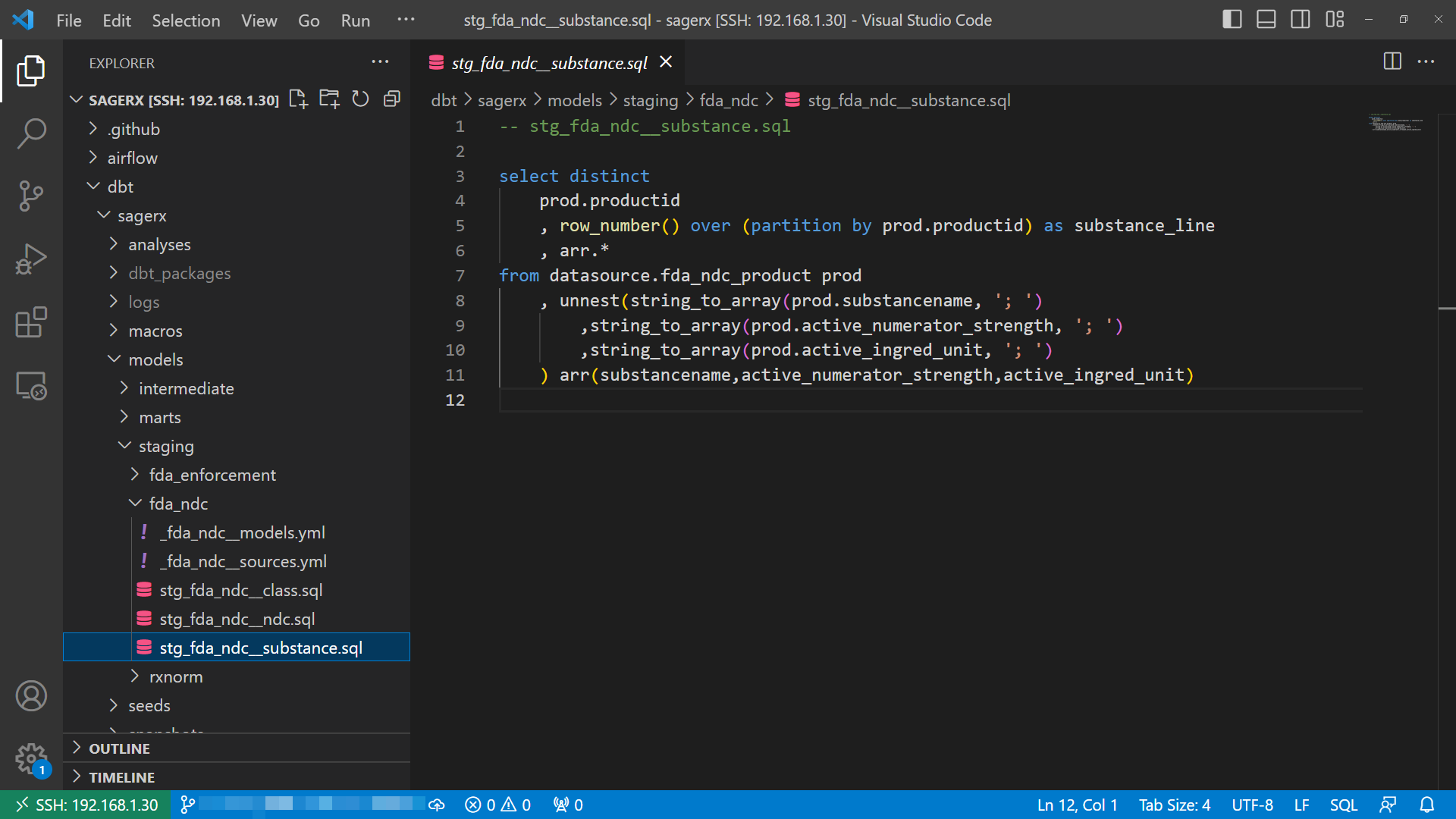
Data build tool (commonly known as dbt) is where the Transformation (T) of the Extract-Load-Transform (ELT) data engineering process happens.
The steps of the dbt process line up nicely with schemas in Postgres. The two main schemas populated by dbt are staging and intermediate.
Staging
The staging step is where normalization of data generally happens (i.e. converting to NDC11, formatting date columns as DATE data types, etc).
It is also where basic data modeling begins happening. If the datasource schema contains raw energy and quarks, the staging schema condenses and refines this material into individual atoms we will use to build more intricate and useful structures. Some examples:
FDA NDC Directory - Class tables in this schema have one row per drug class per product. In the raw data, this information is crammed into a single cell, delimited by semicolons.
NLM RxNorm - Major transformation of RxNorm data happens at this step. Raw RxNorm tables are converted into data models representing NDCs, clinical products, brand products, ingredients, dose forms, etc.
CMS NADAC - De-duplication of data happens at this step. Additionally, differences in percentage and dollars is calculated between each price change reported in the NADAC data.
Intermediate
The intermediate schema uses the building blocks of the staging schema to create more complex, and sometimes more useful, data models. Continuing the raw energy → atoms analogy, the intermediate schema is where we use the atoms from the staging schema to create molecules.
Some examples of intermediate tables:
NLM RxNorm - The intermediate schema of RxNorm data contains extremely useful tables that let you go from NDC to clinical product information (ingredients, dose forms, etc) with a single select statement.
CMS NADAC - This table contains data from the NADAC staging table, but filtered to only current prices based on the current flag defined in the staging table.
Documentation
Documentation is a first class citizen in dbt (and SageRx), and helps support the understanding of the transformations that happen so that (in addition to the underlying queries being open source) end users can feel confident when using the resulting data.
Documentation lives in YAML files inside of the folders of the models/ directory, but dbt also generates a user-friendly website (dbt docs generate) that can be hosted (dbt docs serve - pending Docker integration) to make documentation easily accessible to consumers of the data.
Seeds
Seeds are a dbt feature, and are meant to be small CSV files that can be loaded as tables in a different seeds schema.
SageRx doesn't currently utilize seeds for much, but one potential use could be a repository of "fixes" or "flags" for incorrect or out of date open data (i.e. take the raw source data and “patch” it with corrections or modifications stored in seeds).
Macros
Macros are a dbt feature that utilizes Jinja 2 templating to allow you to create SQL "functions" or easily re-usable SQL code that can be updated in one place and instantly update all the models where it is used.
Conclusion
If you’re still reading this, it probably means you have experience or are interested in the technical building blocks used to build a data pipeline. Hopefully I did a good enough job explaining the tools we chose to make ours (there are many others out there). I’m definitely open to feedback from anyone experienced in this area if it could make SageRx more useful or easier to maintain.
I touched a little on how our data pipeline addressed things specific to open drug data sources, but I plan to dig into the drug data-specific examples in a future post - specifically about RxNorm. If you’re not subscribed already, please subscribe now to follow along and get updates in your inbox.
Thanks for reading!
🌿