
Work smarter not harder: Extracting 40,000 DailyMed labels

Post inspired by CodeRx contributing member Yevgeny Bulochnik and his work on extract_zips.py.
This post is specific to work members of the CodeRx team are doing on the DailyMed API project, but the fundamental concepts apply to a lot of things in any “knowledge worker” job, and certainly in many areas of healthcare as well. The specific issue we were facing is that DailyMed offers a full download of all its structured product labels (SPLs), but they are provided as four separate zip files which each have thousands of other zip files in them, which each have label images in addition to the label XML data.
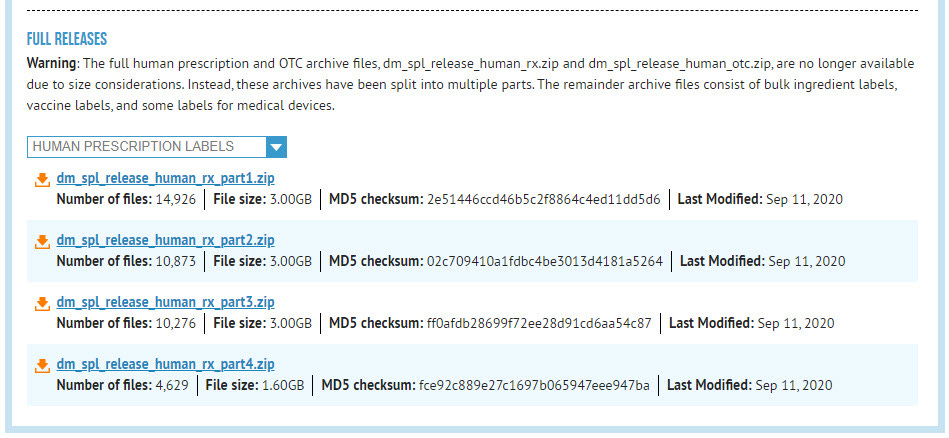
We need to unizp the main four files, and then unzip only the XML file (not the image files) from the 40,000 other zip files inside of them. The manual option for this work is horrible. Best case scenario: you could unzip the four files in your operating system of choice, then (at least with Windows 10) highlight all 40,000 files and right-click-drag them into a new folder and select to extract them there. You would have to click through 40,000 pop-up windows asking if you want to extract each file, and then you would still have to go into each unzipped folder to pull out the XML file. Certainly someone more adept at unzipping files this way could probably point out a more efficient way, but this is still “click heavy” and anyone who works in healthcare IT knows that clicks are the enemy.
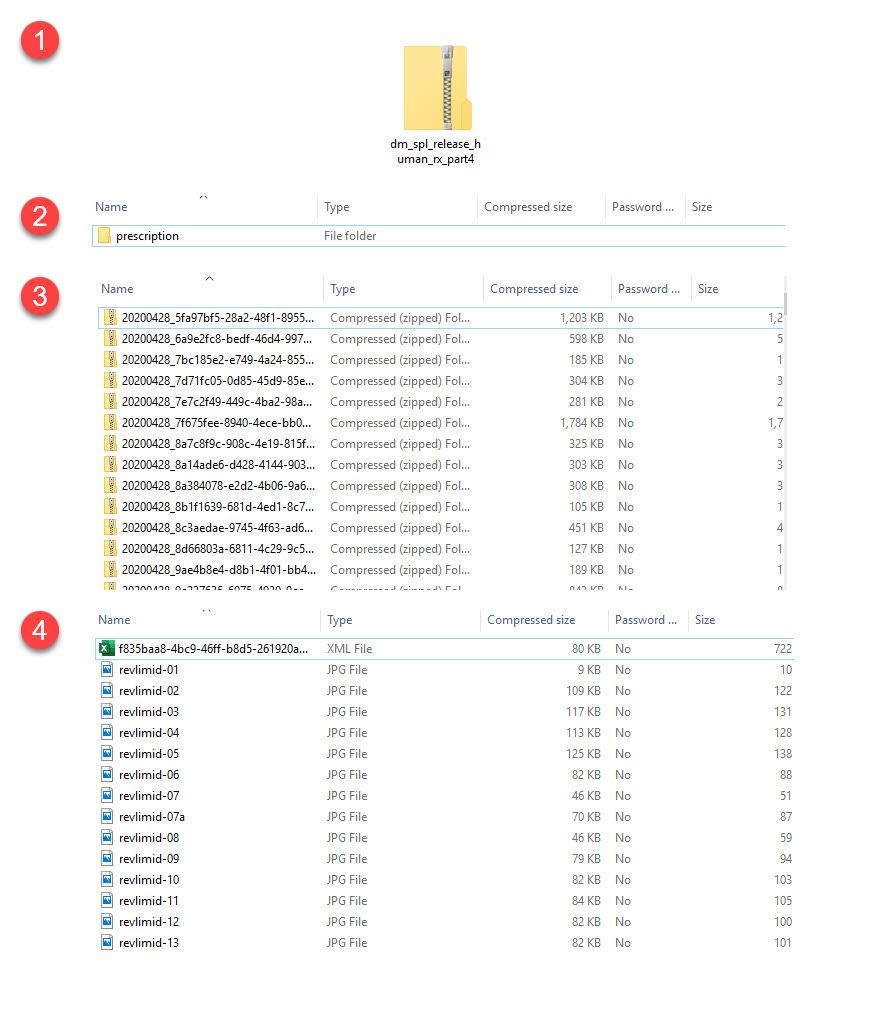
Additionally, we need to do this every month because DailyMed publishes full releases with new and updated label information at least monthly. So anything we decide to do is going to be perpetuated at least 12 times per year. If there is manual work involved, you will need to train someone on the steps and make sure they do it the same way every time. Confronted with a problem like this, my instinct is to do more work up front to reduce maintenance and repetitive human actions down the line. This is where having a toolbox of skills related to automation and efficiency is very valuable. One of these tools is a programming language called Python. With fewer than 15 lines of code, I can do the same work above faster, more efficiently, and with zero clicks. Don’t believe me? Keep reading.
This isn’t a programming lesson, and if you’ve never seen Python code before, this will look scary. But I’ll explain it at a basic level so it makes a little more sense.
from io import BytesIO
import zipfile
from pathlib import Path
current_file_directory = Path(__file__).parent.absolute()
zip_file_directory = current_file_directory / 'zip'
xml_file_directory = zip_file_directory / 'xml'
main_zip_file = list(zip_file_directory.glob('*.zip'))[0]
with zipfile.ZipFile(main_zip_file) as zip_main:
for spl_zip_files in zip_main.namelist():
spl_zip_data = BytesIO(zip_ref.read(spl_zip_files))
with zipfile.ZipFile(spl_zip_data) as zip_spl:
for unzip_file in zip_spl.namelist():
if unzip_file.endswith('xml'):
zip_spl.extract(unzip_file, xml_file_directory)The first thing to know about Python is that a ton of people way smarter than I’ll ever be have done most of the heavy lifting in terms of building modules that you can just import into your scripts to do the hard work for things like unzipping files. The first few lines just import those modules into the script.
from io import BytesIO
import zipfile
from pathlib import PathThe next few lines just tell the script the file structure you are expecting and where to look for one of the four main zip files you downloaded from DailyMed. For simplicity, we are only working on one zip file, but you could loop through all four files just as easily.
current_file_directory = Path(__file__).parent.absolute()
zip_file_directory = current_file_directory / 'zip'
xml_file_directory = zip_file_directory / 'xml'
main_zip_file = list(zip_file_directory.glob('*.zip'))[0]Now for the fun part. You don’t need to know the specifics of what the code below does, but just think conceptually about how a script would loop through the files in the file structure image above.
with zipfile.ZipFile(main_zip_file) as zip_main:
for spl_zip_files in zip_main.namelist():
spl_zip_data = BytesIO(zip_ref.read(spl_zip_files))
with zipfile.ZipFile(spl_zip_data) as zip_spl:
for unzip_file in zip_spl.namelist():
if unzip_file.endswith('xml'):
zip_spl.extract(unzip_file, xml_file_directory)We need to start with the main zip file.
with zipfile.ZipFile(main_zip_file) as zip_main:
...
Then, we need to get a list of all the zip files within the main zip file.
...
for spl_zip_files in zip_main.namelist():
spl_zip_data = BytesIO(zip_ref.read(spl_zip_files))
with zipfile.ZipFile(spl_zip_data) as zip_spl:
...
And finally, we need to look at all the files within each of those zip files and only unzip the files that end with “.xml” which would be the XML files we are looking for.
...
for unzip_file in zip_spl.namelist():
if unzip_file.endswith('xml'):
zip_spl.extract(unzip_file, xml_file_directory)
This script takes only a minute or two to run (even on my ancient pharmacy school issued laptop from 2006 that I use as a development server) and outputs a folder with all the XML files we need to work with for each zip file in the DailyMed full release. All with zero clicks.