
Working with Medicare Part D prescription drug data
Where the only consistency is inconsistency

This is a great example of how gnarly it can be to work with public data sources in an automated manner.
Per a request from Benjamin Jolley, I started working on pulling data from the Medicare Part D Prescription Drug Plan Formulary, Pharmacy Network, and Pricing Information data source into SageRx.
I went after the quarterly release files because they were the only ones with pricing information.
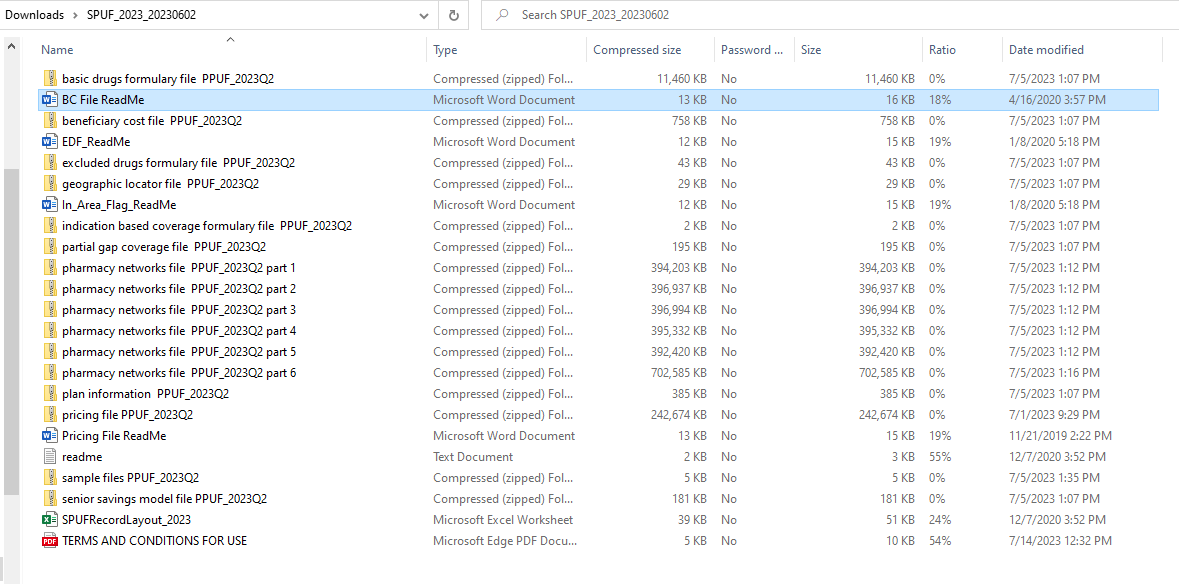
Here is a list of barriers I had to overcome:
The zip files were encoded in a weird deflate64 format - likely because someone at CMS just puts the files in a folder on a Windows machine, right clicks, and selects "Send to zip file" when they are putting this data together for a release. I discovered that the normal Python
zipfilepackage does not handle this format and had to add a separatezipfile-deflate64package as a dependency to the project in order to work with this data… which is kind of a bummer because I’m trying to keep the dependencies to a minimum.Once unzipped, the pipe-delimited text files contained within the zip files have a slightly different naming convention than then names of the zip files themselves AND they aren’t even consistently formatted within themselves. Examples below:
Only one text file is capitalized (i.e. “Indication Based Coverage Formulary File…”) vs all the other files being lower case (i.e. “excluded drugs formulary file…”). A minor inconvenience to standardization.
Some of the text files have one space before “ PPUF” while others have two spaces before “ PPUF”. This is extra annoying because it means you have to treat individual files differently vs just looping through them somehow. Or I guess I could do some RegEx and renaming of the files to clean all of this up.
All of the text files, once unzipped, were in UTF-8 encoding EXCEPT FOR ONE which was in ANSI formatting for some reason. And I had to figure out that Postgres does not support copying ANSI encoded data so I had to use a WIN1252 encoding format just for this file.
All of the files except one had “file” in their name (i.e. “pricing file” and “pharmacy networks file” vs “plan information”), which wouldn’t be a huge deal if it weren’t for my OCD.
The naming of the quarterly zip files has a date in the file name (which means we need to know the date to download new files), but the only pattern I can figure out is below… which is kind of a weird pattern to automate.
Q1 seems to be the second Friday in March
Q2 seems to be the first Friday in June
Q3 seems to be the second Friday in September
Q4 seems to be the first Friday in December
Instead of being consistent and containing the date like the exterior zip files (i.e. “20230602”, the INTERIOR zip files contain the year and quarter number (i.e. “2023Q2”). This isn’t a huge deal - it just means that I have to take an extra step to calculate the quarter number from the date to automate this part, which has to be custom code since I don’t think this is commonly available in Python packages that work with dates.
Due to their massive size, the pharmacy network data is split into six different zip files, but I’m assuming it should all be contained in a single table to make it easy to work with. So I decided to unzip all the files and combine them into a single table instead of creating six different tables.
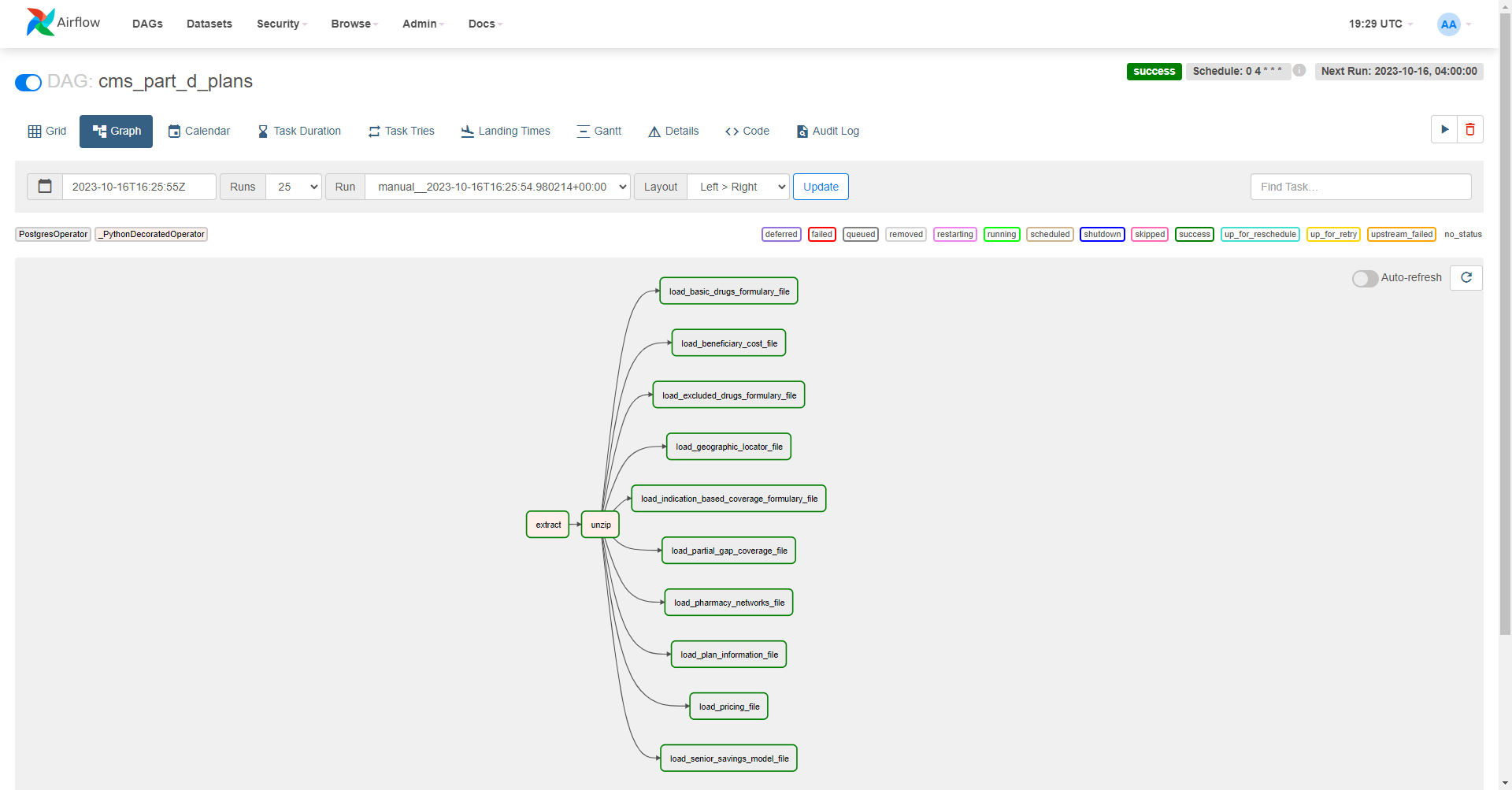
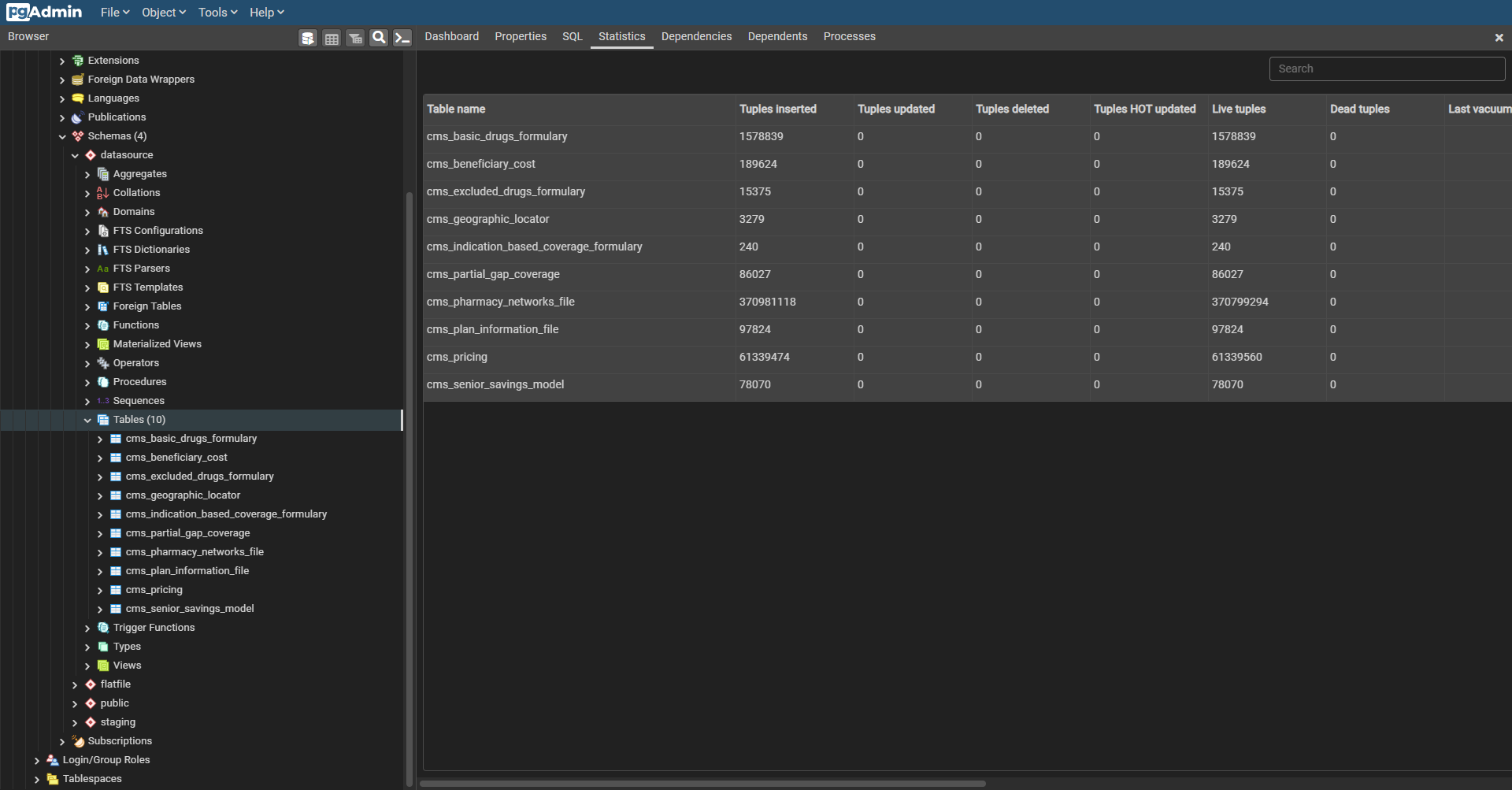
Here’s the finished product. Unzipped and loaded into the database, it takes up about 40 GB of storage space… which is a lot compared to other open data sources. Definitely lots of optimizations to make, but at least it’s all loaded. Now to start transforming it…
If you want to learn more about SageRx, please read through some of my earlier posts or check out the GitHub repo. Until I submit a PR, you can review the branch I created for this work. Thanks for reading!
🌿
Thanks for taking this on, Joey!